OpenShift Metro Disaster Recovery with Advanced Cluster Management
- 1. Overview
- 2. Deploy and Configure ACM for Multisite connectivity
- 3. Red Hat Ceph Storage Installation
- 4. OpenShift Data Foundation Installation
- 5. Install ODF Multicluster Orchestrator Operator on Hub cluster
- 6. Configure SSL access between S3 endpoints
- 7. Enabling Multicluster Web Console
- 8. Create Data Policy on Hub cluster
- 9. Configure DRClusters for Fencing automation
- 10. Create Sample Application for DR testing
- 11. Application Failover between managed clusters
- 12. Application Failback between managed clusters
1. Overview
The intent of this guide is to detail the Metro Disaster Recovery (Metro DR) steps and commands necessary to be able to failover an application from one OpenShift Container Platform (OCP) cluster to another and then failback the same application to the original primary cluster. In this case the OCP clusters will be created or imported using Red Hat Advanced Cluster Management or RHACM and have distance limitations between the OCP clusters of less than 10ms RTT latency.
The persistent storage for applications will be provided by an external Red Hat Ceph Storage (RHCS) cluster stretched between the two locations with the OCP instances connected to this storage cluster. An arbiter node with a storage monitor service will be required at a third location (different location than where OCP instances are deployed) to establish quorum for the RHCS cluster in the case of a site outage. This third location does not have distance limitations and can be 100+ RTT latency from the storage cluster connected to the OCP instances.
This is a general overview of the Metro DR steps required to configure and execute OpenShift Disaster Recovery (ODR) capabilities using OpenShift Data Foundation (ODF) v4.11 and RHACM v2.5 across two distinct OCP clusters separated by distance. In addition to these two cluster called managed clusters, there is currently a requirement to have a third OCP cluster that will be the Advanced Cluster Management (ACM) hub cluster.
These steps are considered Technical Preview in ODF 4.11 and are provided for POC (Proof of Concept) purposes. OpenShift Metro DR will be supported for production usage in a future ODF release.
|
-
Install the ACM operator on the hub cluster.
After creating the OCP hub cluster, install from OperatorHub the ACM operator. After the operator and associated pods are running, create the MultiClusterHub resource. -
Create or import managed OCP clusters into ACM hub.
Import or create the two managed clusters with adequate resources for ODF (compute nodes, memory, cpu) using the RHACM console. -
Install Red Hat Ceph Storage Stretch Cluster With Arbiter.
Properly set up a Ceph cluster deployed on two different datacenters using the stretched mode functionality. -
Install ODF 4.11 on managed clusters.
Install ODF 4.11 on primary and secondary OCP managed clusters and connect both instances to the stretched Ceph cluster. -
Install ODF Multicluster Orchestrator on the ACM hub cluster.
Install from OperatorHub on the ACM hub cluster the ODF Multicluster Orchestrator. The OpenShift DR Hub operator will also be installed. -
Configure SSL access between S3 endpoints
If managed OpenShift clusters are not using valid certificates this step must be done by creating a new user-ca-bundle ConfigMap that contains the certs. -
Enable Multicluster Web Console.
This is a new Tech Preview capability that is required before creating a DRPolicy. It is only needed on the Hub cluster where ACM resides. -
Create one or more DRPolicy
Use the All Clusters Data Services UI to create DRPolicy by selecting the two managed clusters the policy will apply to. -
Validate OpenShift DR Cluster operators are installed.
Once the first DRPolicy is created this will trigger the DR Cluster operators to be created on the two managed clusters selected in the UI. -
Configure DRClusters for fencing automation.
This configuration is in preparation of enabling Fenced prior to application failover. The DRCluster resources will be edited on the Hub cluster to include a new CIDR section and additional DR annotations. -
Create the Sample Application using ACM console.
Use the sample app example from github.com/RamenDR/ocm-ramen-samples to create a busybox deployment for failover and failback testing. -
Validate Sample Application deployment.
Using CLI commands on both managed clusters validate that the application is running. -
Apply DRPolicy to Sample Application.
Use the All Clusters Data Services UI to apply the new DRPolicy to the Sample Application. Once applied a DRPlacementControl resource will be created in the application namespace on the Hub cluster. -
Failover Sample Application to secondary managed cluster.
After fencing the primary managed cluster, modify the application DRPlacementControl resource on the Hub Cluster, add the action of Failover and specify the failoverCluster to trigger the failover. -
Failback Sample Application to primary managed cluster.
After unfencing the primary managed cluster and rebooting worker nodes, modify the application DRPlacementControl resource on the Hub Cluster and change the action to Relocate to trigger a failback to the preferredCluster.
2. Deploy and Configure ACM for Multisite connectivity
This installation method requires you have three OpenShift clusters that have network reachability between them. For the purposes of this document we will use this reference for the clusters:
-
Hub cluster is where ACM, ODF Multisite-orchestrator and ODR Hub controllers are installed.
-
Primary managed cluster is where ODF, ODR Cluster controller, and Applications are installed.
-
Secondary managed cluster is where ODF, ODR Cluster controller, and Applications are installed.
2.1. Install ACM and MultiClusterHub
Find ACM in OperatorHub on the Hub cluster and follow instructions to install this operator.

Verify that the operator was successfully installed and that the MultiClusterHub is ready to be installed.
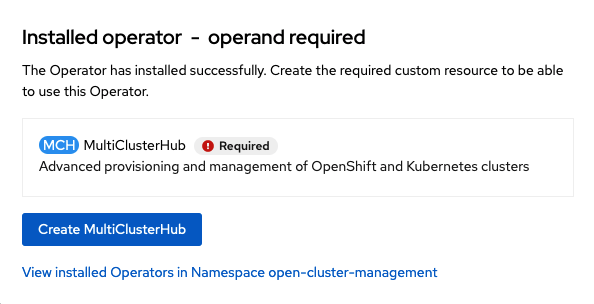
Select MultiClusterHub and use either Form view or YAML view to configure the deployment and select Create.
Most MultiClusterHub deployments can use default settings in the Form view.
|
Once the deployment is complete you can logon to the ACM console using your OpenShift credentials.
First, find the Route that has been created for the ACM console:
oc get route multicloud-console -n open-cluster-management -o jsonpath --template="https://{.spec.host}/multicloud/clusters{'\n'}"This will return a route similar to this one.
https://multicloud-console.apps.perf3.example.com/multicloud/clustersAfter logging in you should see your local cluster imported.
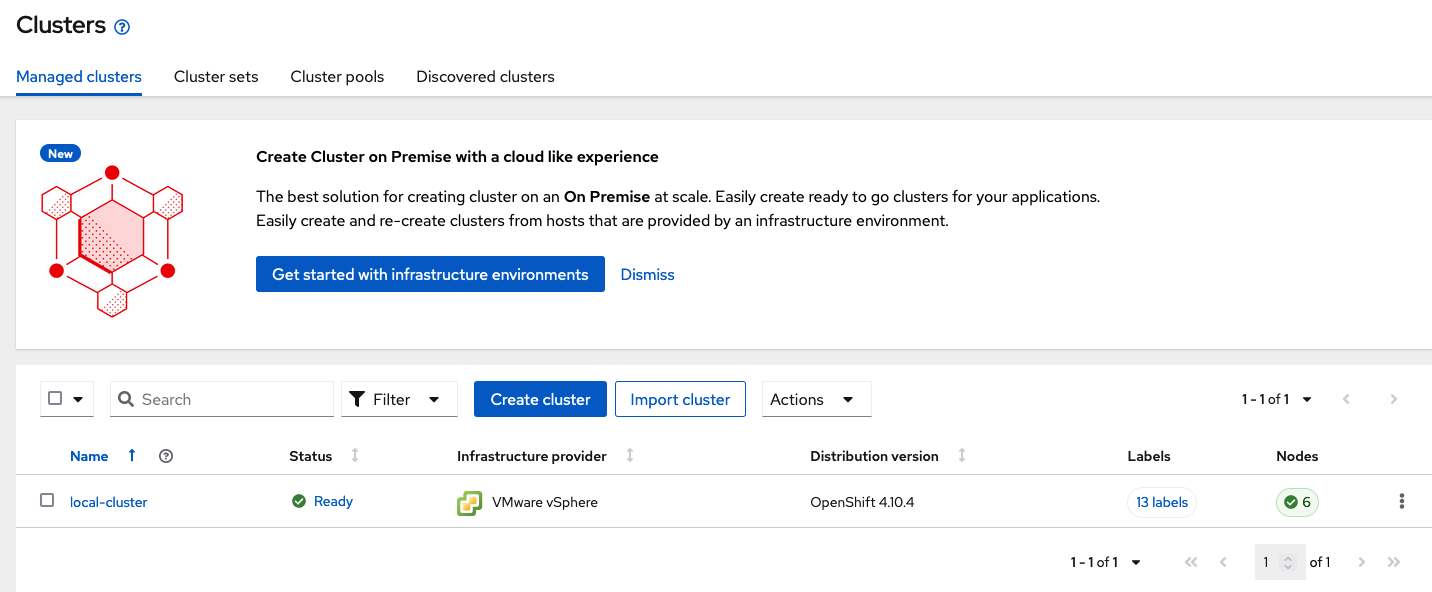
2.2. Import or Create Managed clusters
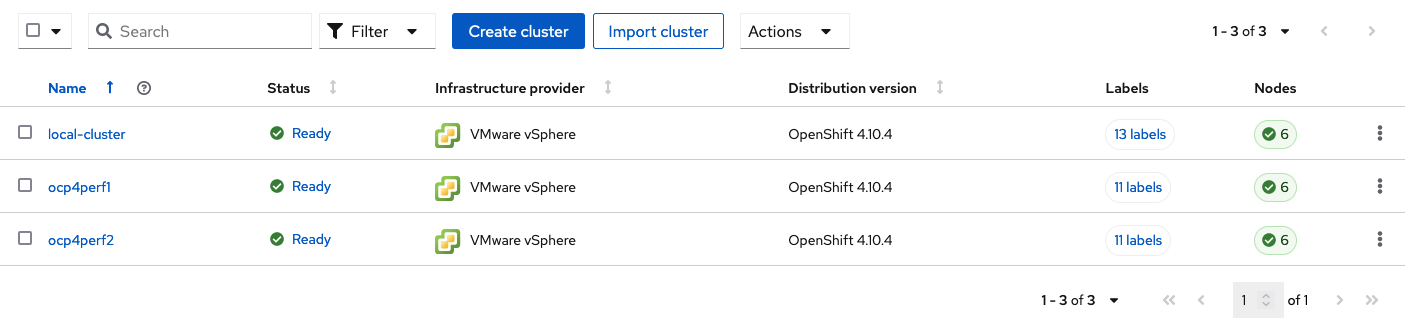
Now that ACM is installed on the Hub cluster it is time to either create or import the Primary managed cluster and the Secondary managed cluster. You should see selections (as in above diagram) for Create cluster and Import cluster. Chose the selection appropriate for your environment. After the managed clusters are successfully created or imported you should see something similar to below.
4. OpenShift Data Foundation Installation
In order to configure storage replication between the two OCP clusters OpenShift Data Foundation (ODF) must be installed first on each managed cluster. ODF deployment guides and instructions are specific to your infrastructure (i.e. AWS, VMware, BM, Azure, etc.).
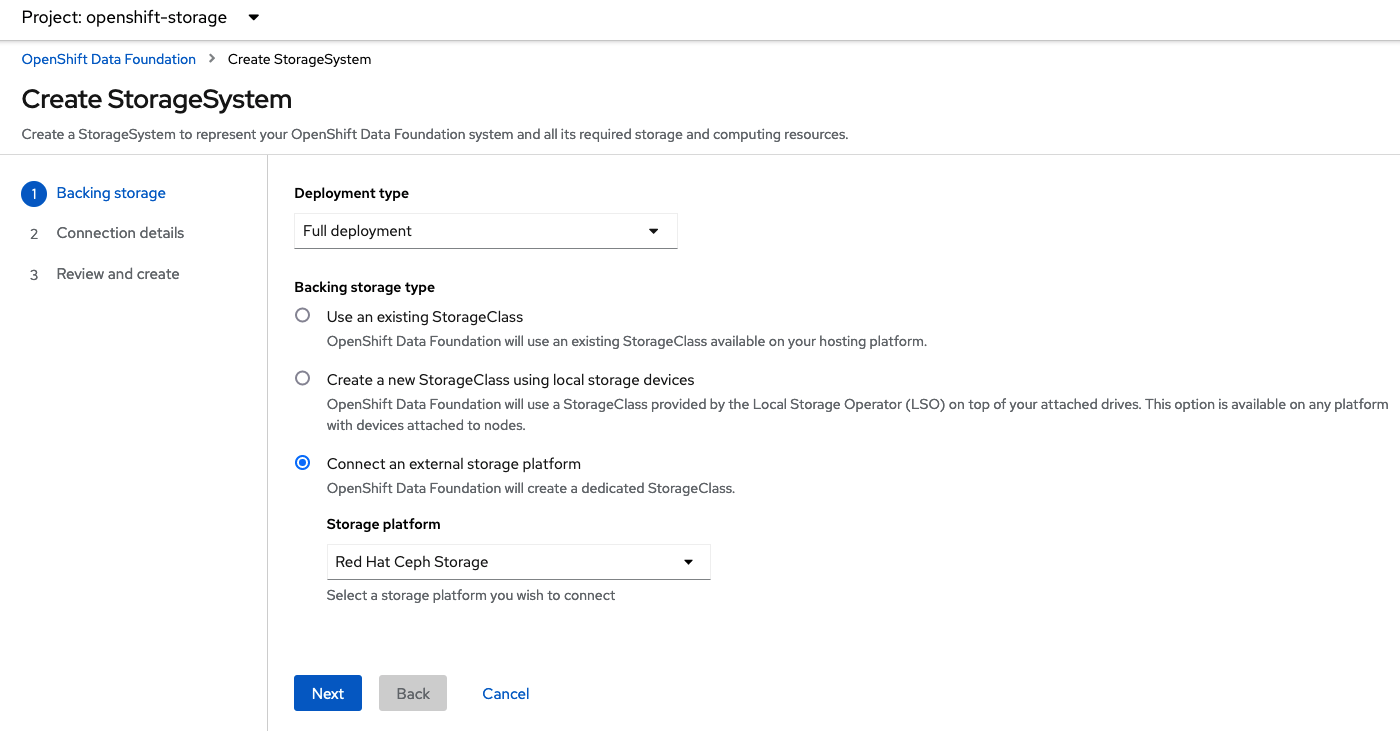
After the ODF operators are installed, select Create StorageSystem and choose Connect an external storage platform and Red Hat Ceph Storage as shown below. Select Next.
Download the ceph-external-cluster-details-exporter.py python script and upload
it to you RHCS bootstrap node, the script needs to be run from a host with the
ceph admin key, in our example the hostname for the RHCS bootstrap node that has the admin keys available is ceph1.
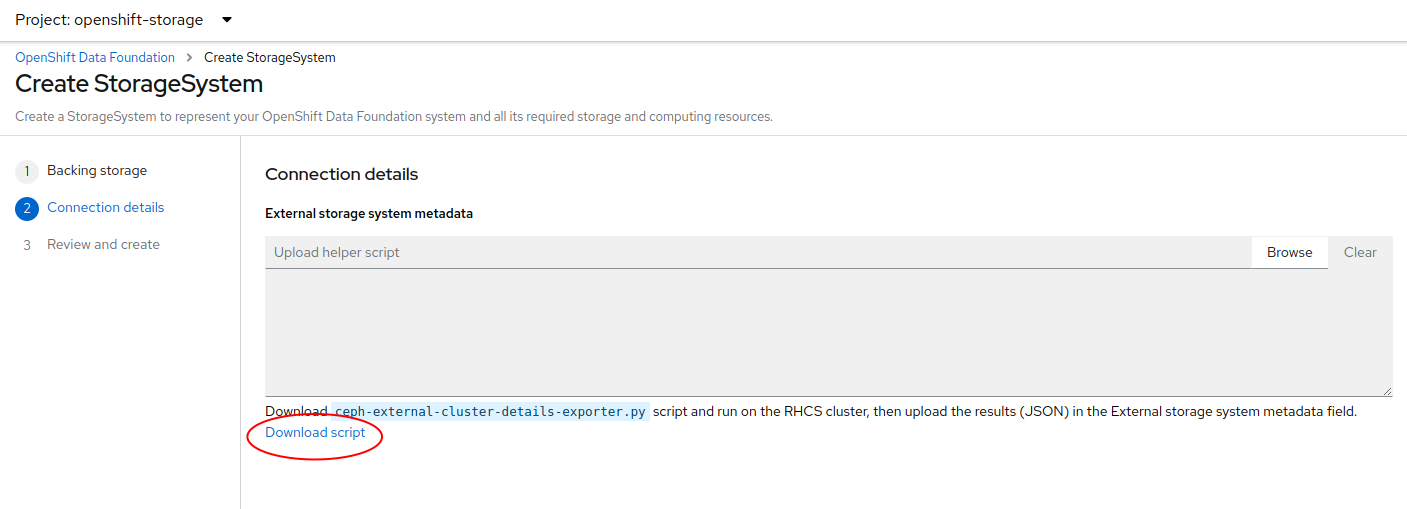
The ceph-external-cluster-details-exporter.py python script will create a configuration file with details for ODF to connect with the RHCS cluster.
Because we are connecting two OCP clusters to the RHCS storage, you need to run the ceph-external-cluster-details-exporter.py script two times, one per OCP cluster.
To see all configuration options available for the ceph-external-cluster-details-exporter.py script run the following command:
python3 ceph-external-cluster-details-exporter.py --helpTo know more about the External ODF deployment options, see ODF external mode deployment.
At a minimum, we need to use the following three flags with the ceph-external-cluster-details-exporter.py script:
-
--rbd-data-pool-name : With the name of the RBD pool we created during RHCS deployment for OCP, in our example, the pool is called
rbdpool. -
--rgw-endpoint : With the RGW IP of the RGW daemon running on the same site as the OCP cluster we are configuring.
-
--run-as-user : With a different client name for each site.
These flags are optional if default values were used during the RHCS deployment:
-
--cephfs-filesystem-name : With the name of the CephFS filesystem we created during RHCS deployment for OCP, the default filesystem name is
cephfs. -
--cephfs-data-pool-name : With the name of the CephFS data pool we created during RHCS deployment for OCP, the default pool is called
cephfs.data. -
--cephfs-metadata-pool-name : With the name of the CephFS metadata pool we created during RHCS deployment for OCP, the default pool is called
cephfs.meta.
Run the following command on the bootstrap node, ceph1, to Get the IP address for the RGW endpoints in datacenter1 and datacenter2:
ceph orch ps | grep rgw.objectgwrgw.objectgw.ceph3.mecpzm ceph3 *:8080 running (5d) 31s ago 7w 204M - 16.2.7-112.el8cp
rgw.objectgw.ceph6.mecpzm ceph6 *:8080 running (5d) 31s ago 7w 204M - 16.2.7-112.el8cphost ceph3
host ceph6ceph3.example.com has address 10.0.40.24
ceph6.example.com has address 10.0.40.66Execute the ceph-external-cluster-details-exporter.py with the parameters configured for our first ocp managed cluster cluster1.
python3 ceph-external-cluster-details-exporter.py --rbd-data-pool-name rbdpool --cephfs-filesystem-name cephfs --cephfs-data-pool-name cephfs.cephfs.data --cephfs-metadata-pool-name cephfs.cephfs.meta --rgw-endpoint 10.0.40.24:8080 --run-as-user client.odf.cluster1 > ocp-cluster1.jsonExecute the ceph-external-cluster-details-exporter.py with the parameters configured for our first ocp managed cluster cluster2
python3 ceph-external-cluster-details-exporter.py --rbd-data-pool-name rbdpool --cephfs-filesystem-name cephfs --cephfs-data-pool-name cephfs.cephfs.data --cephfs-metadata-pool-name cephfs.cephfs.meta --rgw-endpoint 10.0.40.66:8080 --run-as-user client.odf.cluster2 > ocp-cluster2.jsonSave the two files generated in the bootstrap cluster (ceph1) ocp-cluster1.json and ocp-cluster2.json to your local machine. * Use the contents of file ocp-cluster1.json on the OCP console on cluster1 where external ODF is being deployed. * Use the contents of file ocp-cluster2.json on the OCP console on cluster2 where external ODF is being deployed.
The next figure has an example for OCP cluster1.
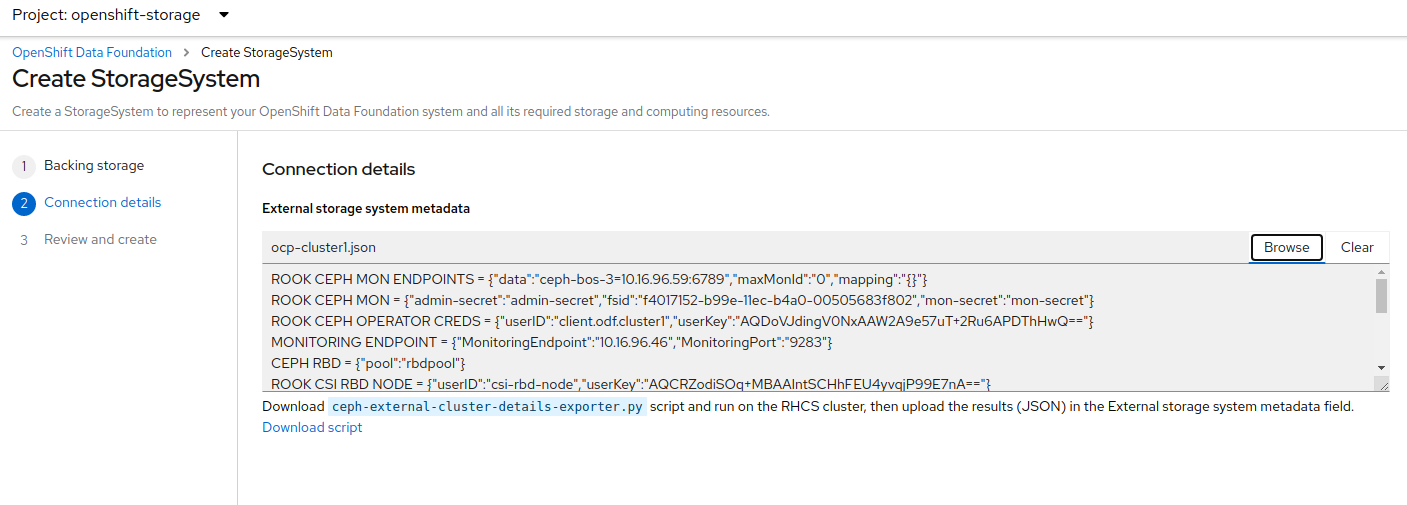
Review the settings and then select Create StorageSystem.
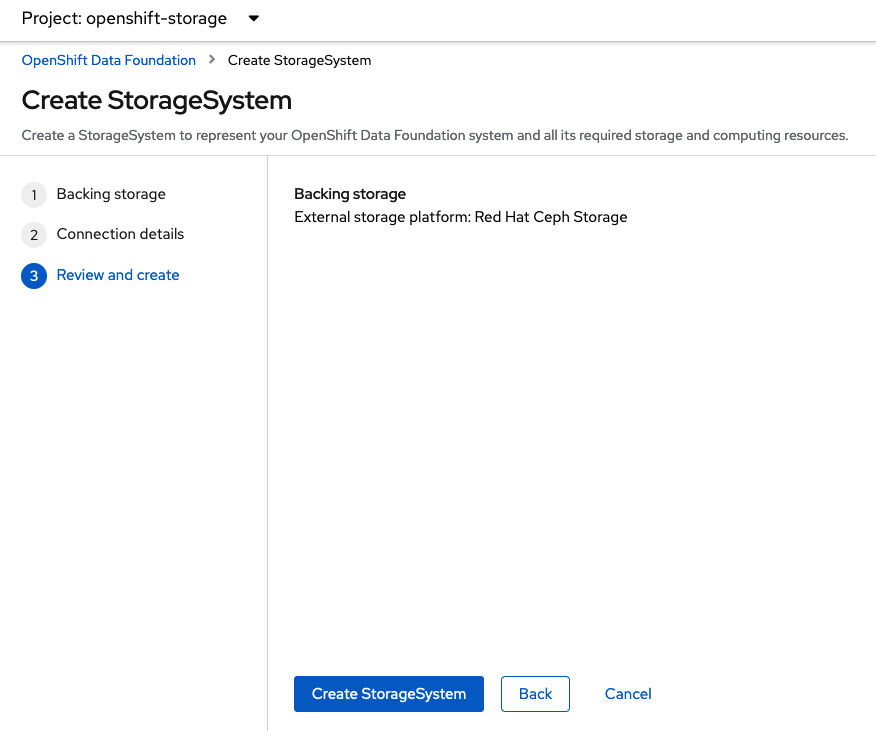
You can validate the successful deployment of ODF on each managed OCP cluster with the following command:
oc get storagecluster -n openshift-storage ocs-external-storagecluster -o jsonpath='{.status.phase}{"\n"}'And for the Multi-Cluster Gateway (MCG):
oc get noobaa -n openshift-storage noobaa -o jsonpath='{.status.phase}{"\n"}'If the result is Ready for both queries on the Primary managed cluster and the Secondary managed cluster continue on to the next step.
| The successful installation of ODF can also be validated in the OCP Web Console by navigating to Storage and then Data Foundation. |
5. Install ODF Multicluster Orchestrator Operator on Hub cluster
On the Hub cluster navigate to OperatorHub and filter for ODF Multicluster Orchestrator. Follow instructions to Install the operator into the project openshift-operators. The ODF Multicluster Orchestrator also installs the Openshift DR Hub Operator on the ACM hub cluster as a dependency.
Check to see the operators Pod are in a Running state. The OpenShift DR Hub operator will be installed at the same time in openshift-operators.
oc get pods -n openshift-operatorsNAME READY STATUS RESTARTS AGE
odfmo-controller-manager-f6fc95f7f-7wtjl 1/1 Running 0 4m14s
ramen-hub-operator-85465bd487-7sl2k 2/2 Running 0 3m40s
odf-multicluster-console-76b88b444c-vl9s4 1/1 Running 0 3m50s6. Configure SSL access between S3 endpoints
These steps are necessary so that metadata can be stored on the alternate cluster in a Multi-Cloud Gateway (MCG) object bucket using a secure transport protocol and in addition the Hub cluster needs to verify access to the object buckets.
| If all of your OpenShift clusters are deployed using signed and valid set of certificates for your environment then this section can be skipped. |
Extract the ingress certificate for the Primary managed cluster and save the output to primary.crt.
oc get cm default-ingress-cert -n openshift-config-managed -o jsonpath="{['data']['ca-bundle\.crt']}" > primary.crtExtract the ingress certificate for the Secondary managed cluster and save the output to secondary.crt.
oc get cm default-ingress-cert -n openshift-config-managed -o jsonpath="{['data']['ca-bundle\.crt']}" > secondary.crtCreate a new YAML file cm-clusters-crt.yaml to hold the certificate bundle for both the Primary managed cluster and the Secondary managed cluster.
| There could be more or less than three certificates for each cluster as shown in this example file. |
apiVersion: v1
data:
ca-bundle.crt: |
-----BEGIN CERTIFICATE-----
<copy contents of cert1 from primary.crt here>
-----END CERTIFICATE-----
-----BEGIN CERTIFICATE-----
<copy contents of cert2 from primary.crt here>
-----END CERTIFICATE-----
-----BEGIN CERTIFICATE-----
<copy contents of cert3 primary.crt here>
-----END CERTIFICATE----
-----BEGIN CERTIFICATE-----
<copy contents of cert1 from secondary.crt here>
-----END CERTIFICATE-----
-----BEGIN CERTIFICATE-----
<copy contents of cert2 from secondary.crt here>
-----END CERTIFICATE-----
-----BEGIN CERTIFICATE-----
<copy contents of cert3 from secondary.crt here>
-----END CERTIFICATE-----
kind: ConfigMap
metadata:
name: user-ca-bundle
namespace: openshift-configThis ConfigMap needs to be created on the Primary managed cluster, Secondary managed cluster, and the Hub cluster.
oc create -f cm-clusters-crt.yamlconfigmap/user-ca-bundle created
The Hub cluster needs to verify access to the object buckets using the DRPolicy resource. Therefore the same ConfigMap, cm-clusters-crt.yaml, needs to be created on the Hub cluster.
|
After all the user-ca-bundle ConfigMaps are created, the default Proxy cluster resource needs to be modified.
Patch the default Proxy resource on the Primary managed cluster, Secondary managed cluster, and the Hub cluster.
oc patch proxy cluster --type=merge --patch='{"spec":{"trustedCA":{"name":"user-ca-bundle"}}}'proxy.config.openshift.io/cluster patched7. Enabling Multicluster Web Console
This is a new capability that is required before creating a Data Policy or DRPolicy. It is only needed on the Hub cluster and RHACM 2.5 must be installed.
| Multicluster console is a Technology Preview feature only. Technology Preview features are not supported with Red Hat production service level agreements (SLAs) and might not be functionally complete. Red Hat does not recommend using them in production. These features provide early access to upcoming product features, enabling customers to test functionality and provide feedback during the development process. |
Enable the feature gate by navigating from Administration → Cluster Settings → Configuration → FeatureGate, and edit the YAML template as follows:
[...]
spec:
featureSet: TechPreviewNoUpgradeClick Save to enable the multicluster console for all clusters in the RHACM console.
| Do not set this feature gate on production clusters. You will not be able to upgrade your cluster after applying the feature gate, and it cannot be undone. |
8. Create Data Policy on Hub cluster
MetroDR uses the DRPolicy resources on the Hub cluster to failover and relocate workloads across managed clusters. A DRPolicy requires a set of two DRClusters or peer clusters connected to the same Red Hat Ceph Storage cluster. The ODF MultiCluster Orchestrator Operator facilitates the creation of each DRPolicy and the corresponding DRClusters through the Multicluster Web console.
On the Hub cluster navigate to All Clusters. Then navigate to Data policies under Data services menu. If this your first DRPolicy created you will see Create DRpolicy at the bottom of the page.
Make sure to login to all clusters from the Multicluster Web console. The clusters will be directly below All Clusters.
|
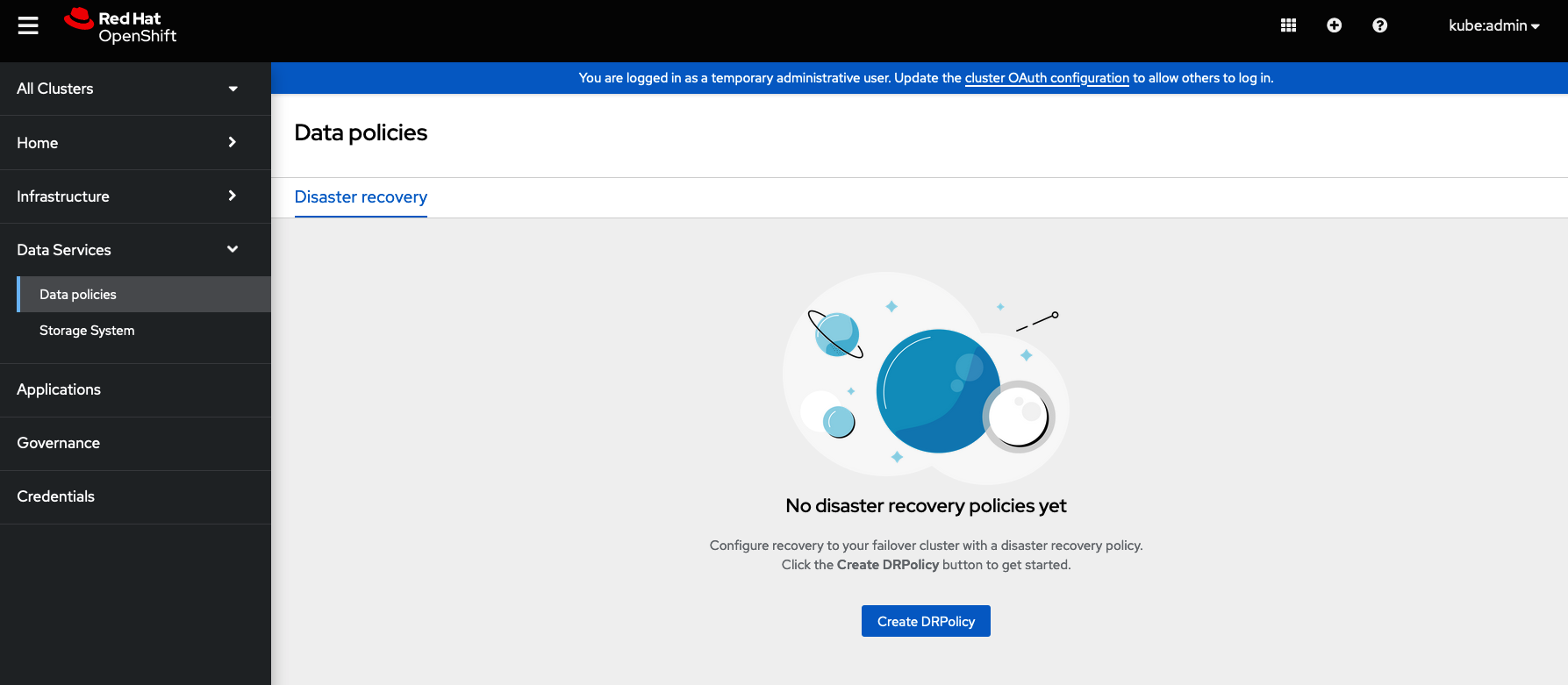
Click on Create DRPolicy. Select the clusters presented from the list of managed clusters that you would like to participate in the DRPolicy and give the policy a unique name (i.e., ocp4perf1-ocp4perf2).
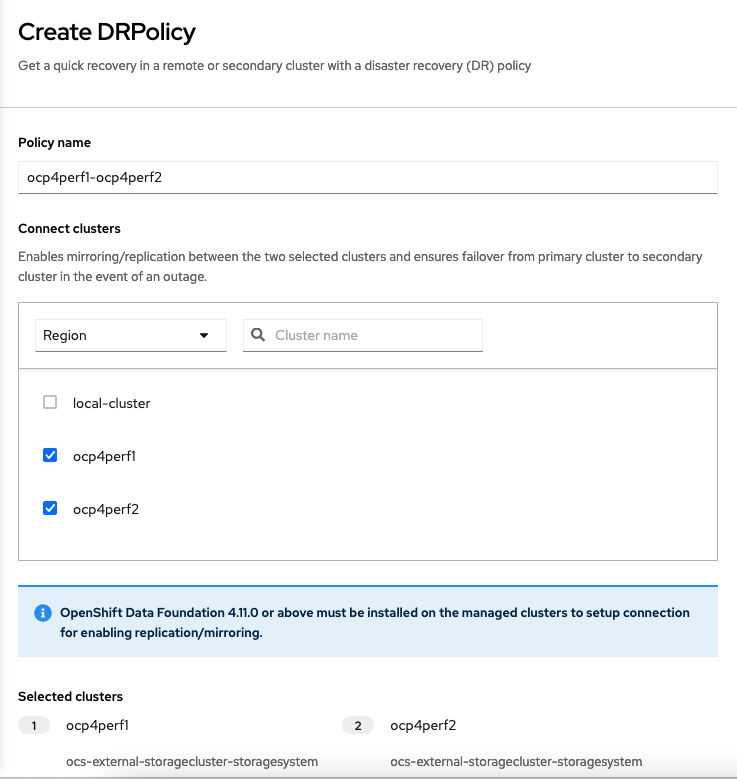
The greyed out dropdown option for Replication policy will automatically be selected as sync based on the OpenShift clusters selected. Select Create.
This should create the two DRCluster resources and also the DRPolicy on the Hub cluster. In addition, when the initial DRPolicy is created the following will happen:
-
An object bucket created (using MCG) on each managed cluster for storing PVC and PV metadata.
-
A Secret created in the
openshift-operatorsproject on the Hub cluster for each new object bucket that has the base64 encoded access keys. -
The
ramen-hub-operator-configConfigMap on the Hub cluster is modified withs3StoreProfilesentries. -
The
OpenShift DR Clusteroperator will be deployed on each managed cluster in theopenshift-dr-systemproject. -
The object buckets Secrets on the Hub cluster in the project
openshift-operatorswill be copied to the managed clusters in theopenshift-dr-systemproject. -
The
s3StoreProfilesentries will be copied to the managed clusters and used to modify theramen-dr-cluster-operator-configConfigMap in theopenshift-dr-systemproject.
To validate that the DRPolicy is created successfully run this command on the Hub cluster for the each DRPolicy resource created.
Replace <drpolicy_name> with your unique name.
|
oc get drpolicy <drpolicy_name> -o jsonpath='{.status.conditions[].reason}{"\n"}'SucceededTo validate object bucket access from the Hub cluster to both the Primary managed cluster and the Secondary managed cluster first get the names of the DRClusters on the Hub cluster.
oc get drclustersNAME AGE
ocp4perf1 4m42s
ocp4perf2 4m42sNow test S3 access to each bucket created on each managed cluster using this DRCluster validation command.
Replace <drcluster_name> with your unique name.
|
oc get drcluster <drcluster_name> -o jsonpath='{.status.conditions[2].reason}{"\n"}'Succeeded| Make sure to run command for both DRClusters on the Hub cluster. |
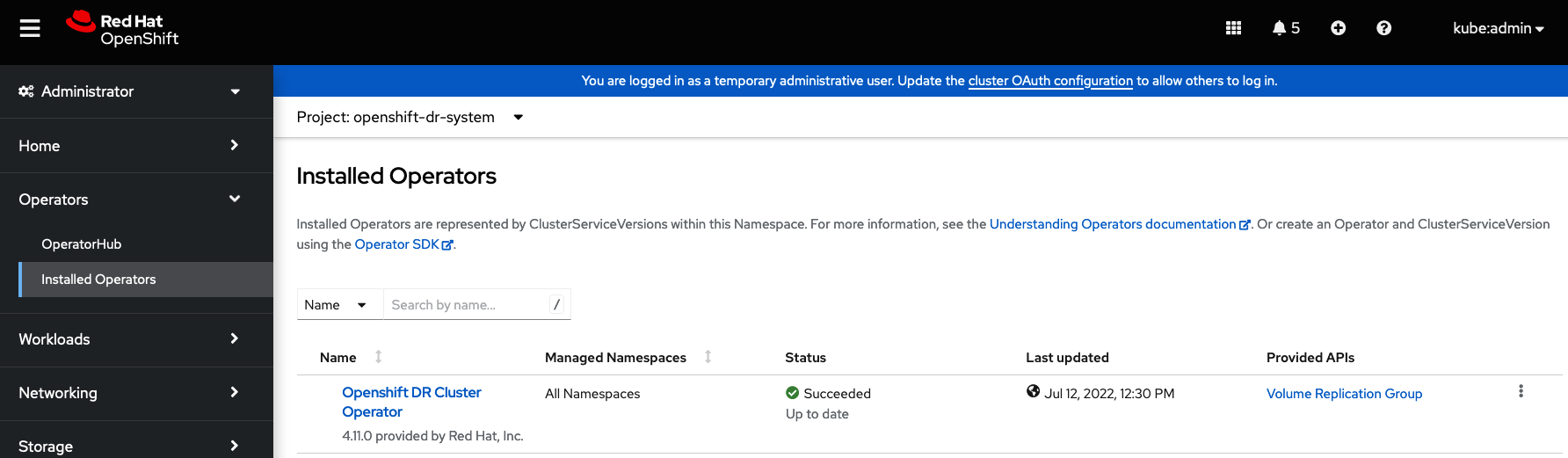
To validate that the OpenShift DR Cluster operator installation was successful on the Primary managed cluster and the Secondary managed cluster do the following command:
oc get csv,pod -n openshift-dr-systemNAME DISPLAY VERSION REPLACES PHASE
clusterserviceversion.operators.coreos.com/odr-cluster-operator.v4.11.0 Openshift DR Cluster Operator 4.11.0 Succeeded
NAME READY STATUS RESTARTS AGE
pod/ramen-dr-cluster-operator-5564f9d669-f6lbc 2/2 Running 0 5m32sYou can also go to OperatorHub on each of the managed clusters and look to see the OpenShift DR Cluster Operator is installed.
9. Configure DRClusters for Fencing automation
This configuration is in preparation of enabling Fenced prior to application failover.
9.1. Add Node IP addresses to DRClusters
The first step is to find the IP addresses for all of the OpenShift nodes in the managed clusters.
This can be done by running this command in the Primary managed cluster and the Secondary managed cluster.
oc get nodes -o jsonpath='{range .items[*]}{.status.addresses[?(@.type=="ExternalIP")].address}{"\n"}{end}'10.70.56.118
10.70.56.193
10.70.56.154
10.70.56.242
10.70.56.136
10.70.56.99Once you have the IP addresses then the DRCluster resources can be modified for each managed cluster.
First you need the names of DRCluster to be modified. Execute this command on the Hub Cluster.
oc get drclusterNAME AGE
ocp4perf1 5m35s
ocp4perf2 5m35sNow each DRCluster needs to edited and your unique IP addresse`s added in this way after replacing `<drcluster_name> with your unique name.
oc edit drcluster <drcluster_name>apiVersion: ramendr.openshift.io/v1alpha1
kind: DRCluster
metadata:
[...]
spec:
s3ProfileName: s3profile-<drcluster_name>-ocs-external-storagecluster
## Add this section
cidrs:
- <IP_Address1>/32
- <IP_Address2>/32
- <IP_Address3>/32
- <IP_Address4>/32
- <IP_Address5>/32
- <IP_Address6>/32
[...]Example output.
drcluster.ramendr.openshift.io/ocp4perf1 edited| There could be more than six IP addresses. |
This DRCluster configuration needs to be done also for IP addresses on the Secondary managed clusters in the peer DRCluster resource (e.g., ocp4perf2).
9.2. Add Fencing Annotations to DRClusters
Add the following annotations to all the DRCluster resources. These annotations include details needed for the NetworkFence resource created later in these instructions (prior to testing application failover).
Replace <drcluster_name> with your unique name.
|
oc edit drcluster <drcluster_name>apiVersion: ramendr.openshift.io/v1alpha1
kind: DRCluster
metadata:
## Add this section
annotations:
drcluster.ramendr.openshift.io/storage-clusterid: openshift-storage
drcluster.ramendr.openshift.io/storage-driver: openshift-storage.rbd.csi.ceph.com
drcluster.ramendr.openshift.io/storage-secret-name: rook-csi-rbd-provisioner
drcluster.ramendr.openshift.io/storage-secret-namespace: openshift-storage
[...]drcluster.ramendr.openshift.io/ocp4perf1 edited| Make sure to add these annotations for both DRCluster resources (e.g., ocp4perf1 and ocp4perf2). |
10. Create Sample Application for DR testing
In order to test failover from the Primary managed cluster to the Secondary managed cluster and back again we need a simple application. The sample application used for this example with be busybox.
10.1. Creating Sample Application using ACM console
Start by loggin into the ACM console using your OpenShift credentials if not already logged in.
oc get route multicloud-console -n open-cluster-management -o jsonpath --template="https://{.spec.host}/multicloud/applications{'\n'}"This will return a route similar to this one.
https://multicloud-console.apps.perf3.example.com/multicloud/applicationsAfter logging in select Create application in the top right and choose Subscription.
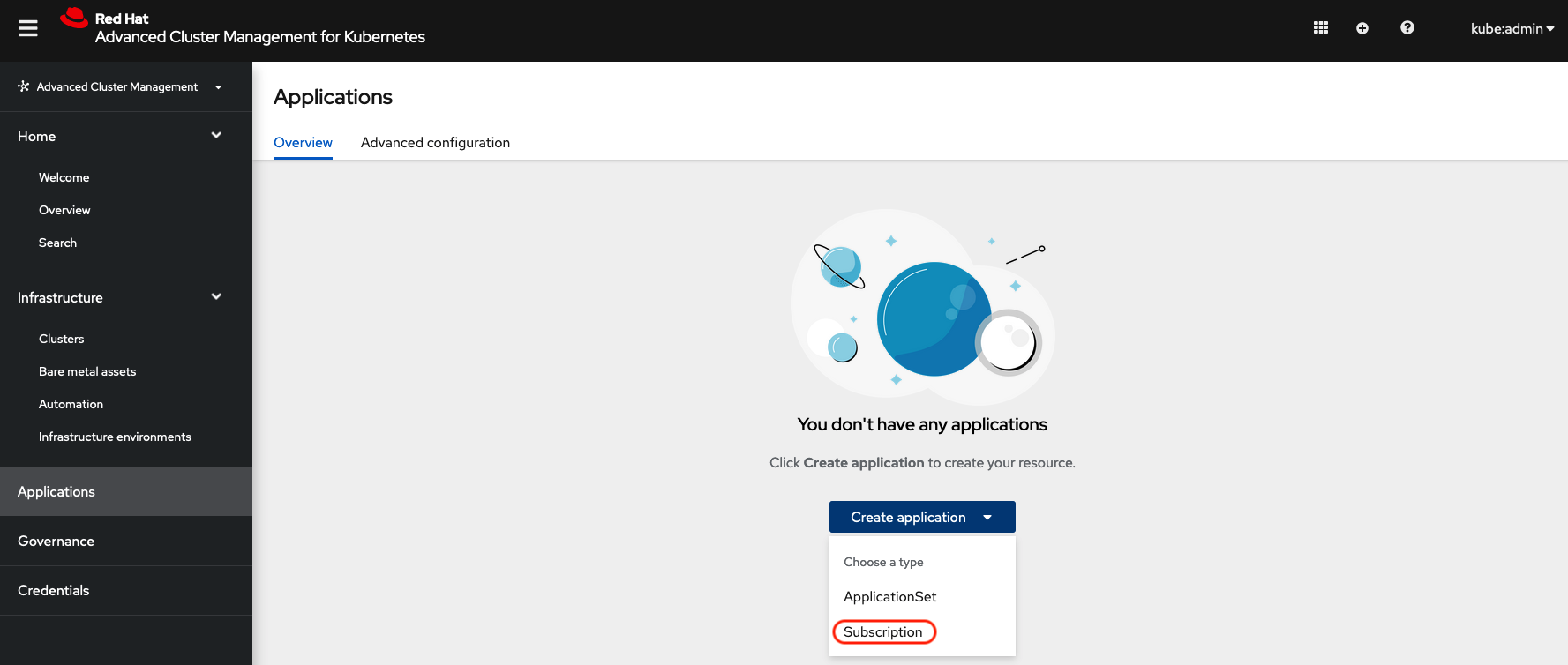
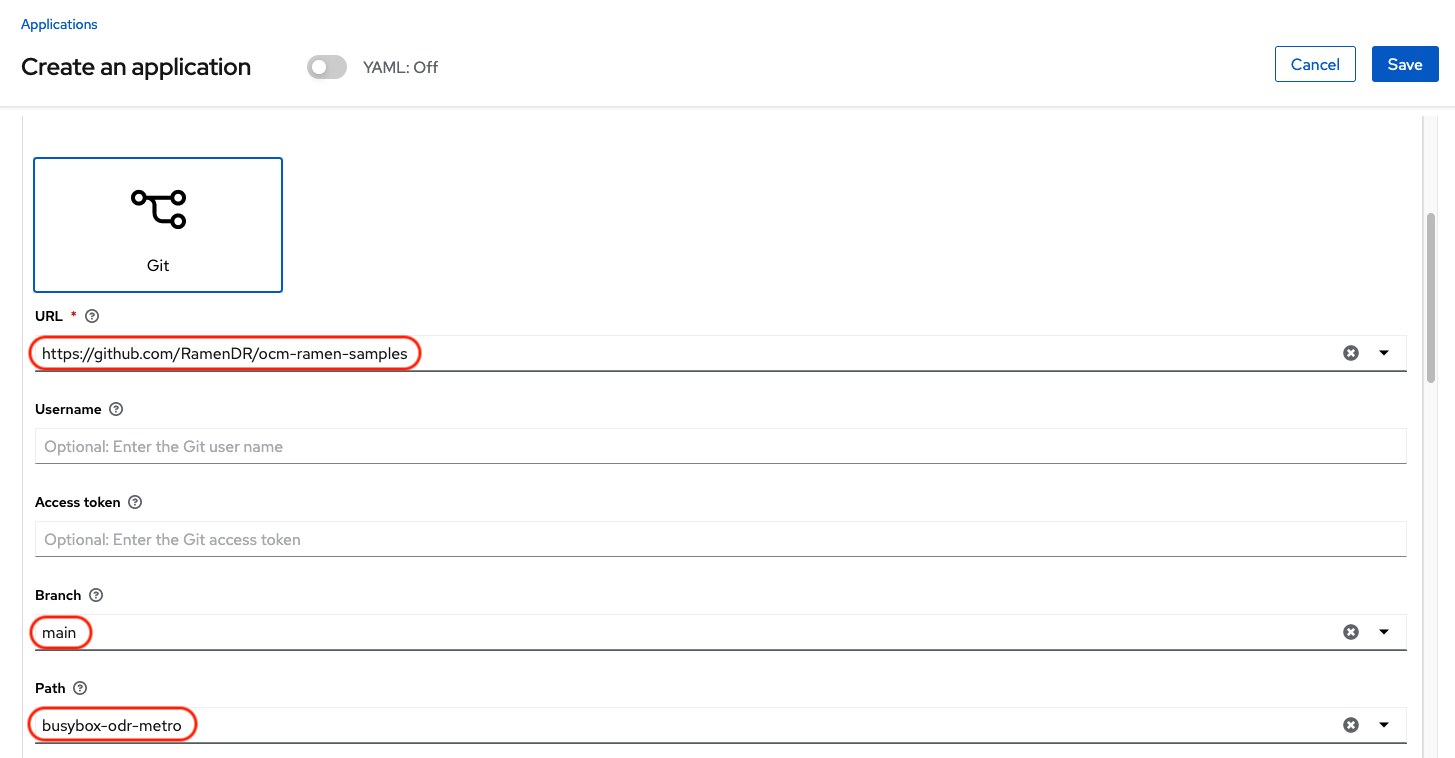
Fill out the top of the Create an application form as shown below and select repository type Git.
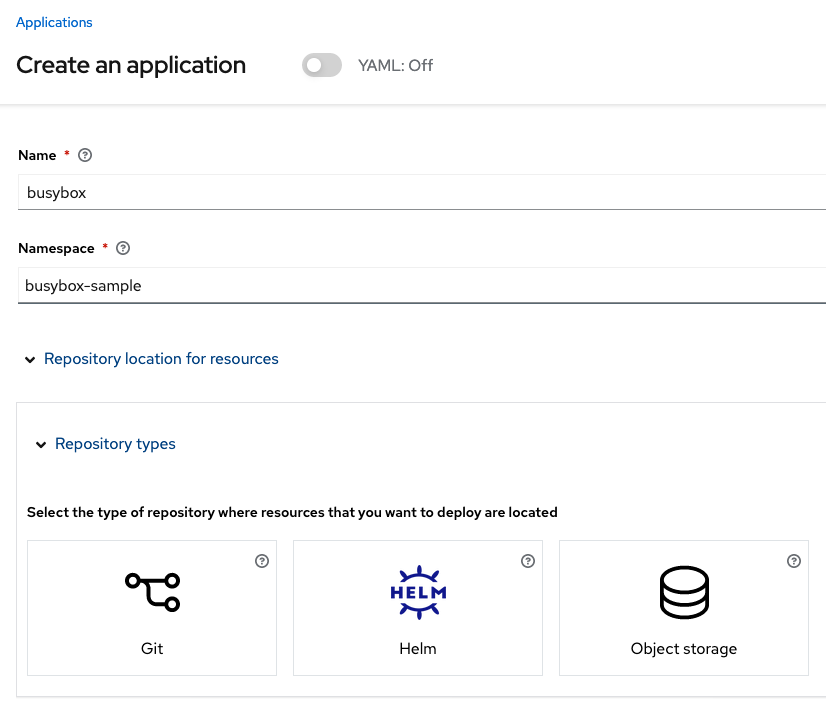
The next section to fill out is below the Git box and is the repository URL for the sample application, the github branch and path to resources that will be created, the busybox Pod and PVC.
Sample application repository github.com/RamenDR/ocm-ramen-samples. Branch is main and path is busybox-odr-metro.
|
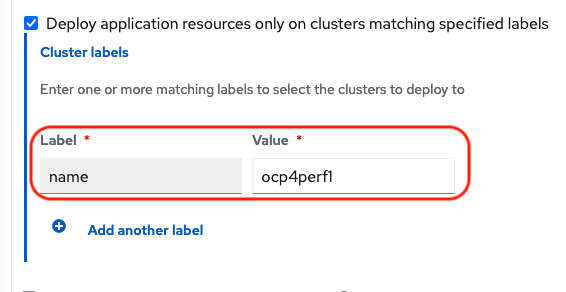
Scroll down in the form until you see Deploy application resources only on clusters matching specified labels and then add a label for the Primary managed cluster name in RHACM cluster list view.
After adding the Label to identify the cluster, select Save in the upper right hand corner.
On the follow-on screen go to the Topology tab. You should see that there are all Green checkmarks on the application topology.
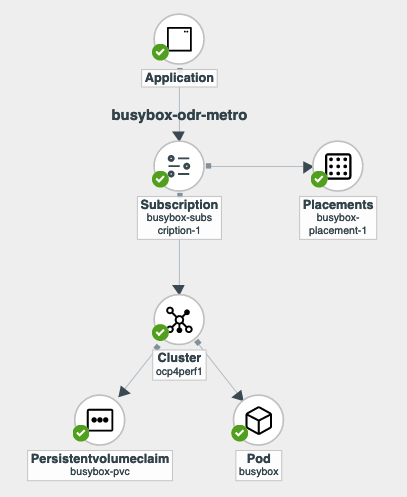
| To get more information click on any of the topology elements and a window will appear to right of the topology view. |
10.2. Validating Sample Application deployment
Now that the busybox application has been deployed to your Primary managed cluster the deployment can be validated.
Logon to your managed cluster where busybox was deployed by ACM. This is most likely your Primary managed cluster.
oc get pods,pvc -n busybox-sampleNAME READY STATUS RESTARTS AGE
pod/busybox 1/1 Running 0 6m
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
persistentvolumeclaim/busybox-pvc Bound pvc-a56c138a-a1a9-4465-927f-af02afbbff37 1Gi RWO ocs-storagecluster-ceph-rbd 6m10.3. Apply DRPolicy to Sample Application
On the Hub cluster go back to the Multicluster Web console and select All Clusters in the top right hand corner.
Make sure to login to all clusters from the Multicluster Web console. The clusters will be directly below All Clusters.
|
Navigate to Data Services and then choose Data policies. You should see the DRPolicy you created earlier in these instructions, section Create Data Policy on Hub cluster. At the far right of the DRPolicy select the vertical dots as shown below.
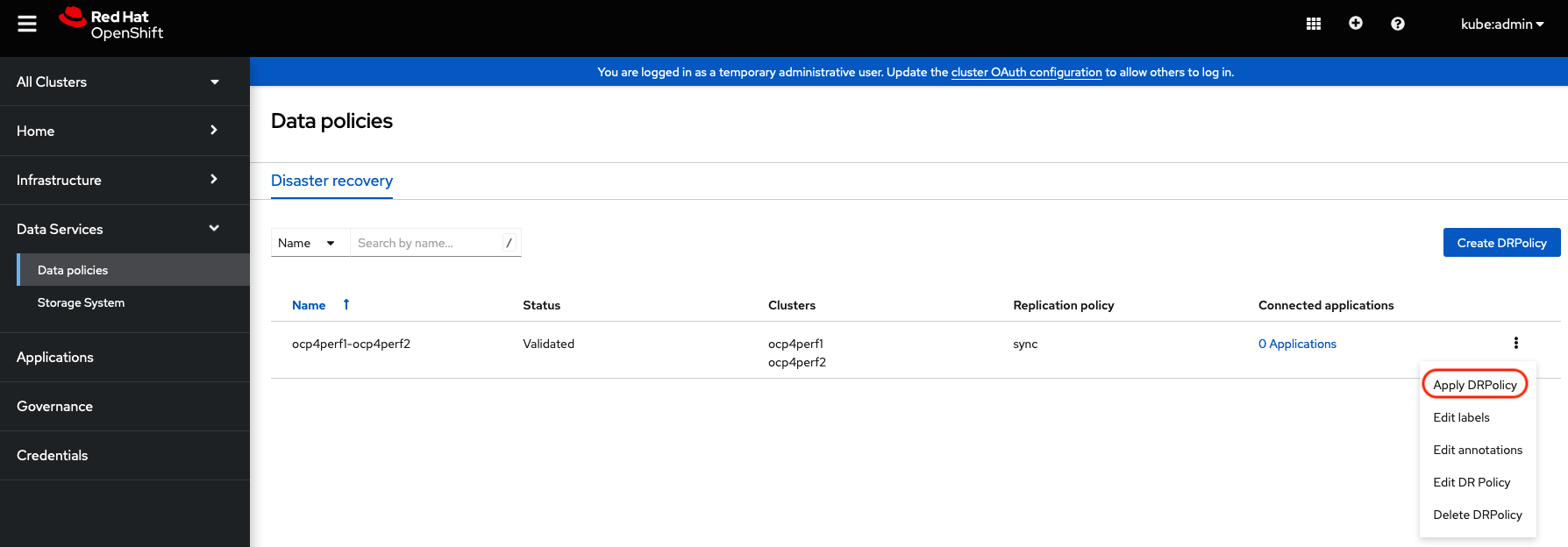
When the Apply DRPolicy box appears select busybox and then Apply.
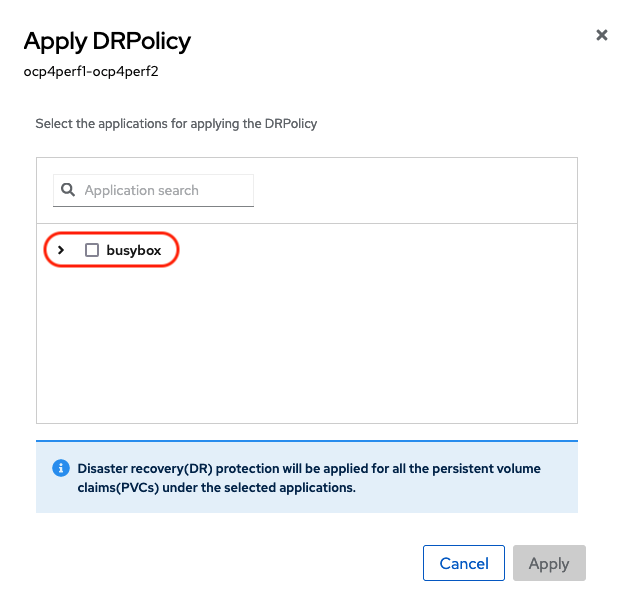
Validate that a DRPlacementControl or DRPC was created in the busybox-sample namespace on the Hub cluster. This resource is used for both failover and failback actions for this application.
oc get drpc -n busybox-sampleNAME AGE PREFERREDCLUSTER FAILOVERCLUSTER DESIREDSTATE CURRENTSTATE
busybox-placement-1-drpc 6m59s ocp4perf1 Deployed10.4. Deleting the Sample Application
Deleting the busybox application can be done using the ACM console. Navigate to Applications and then find the application to be deleted (busybox in this case).
| The instructions to delete the sample application should not be executed until the failover and failback (relocate) testing is completed and you want to remove this application from RHACM and from the managed clusters. |
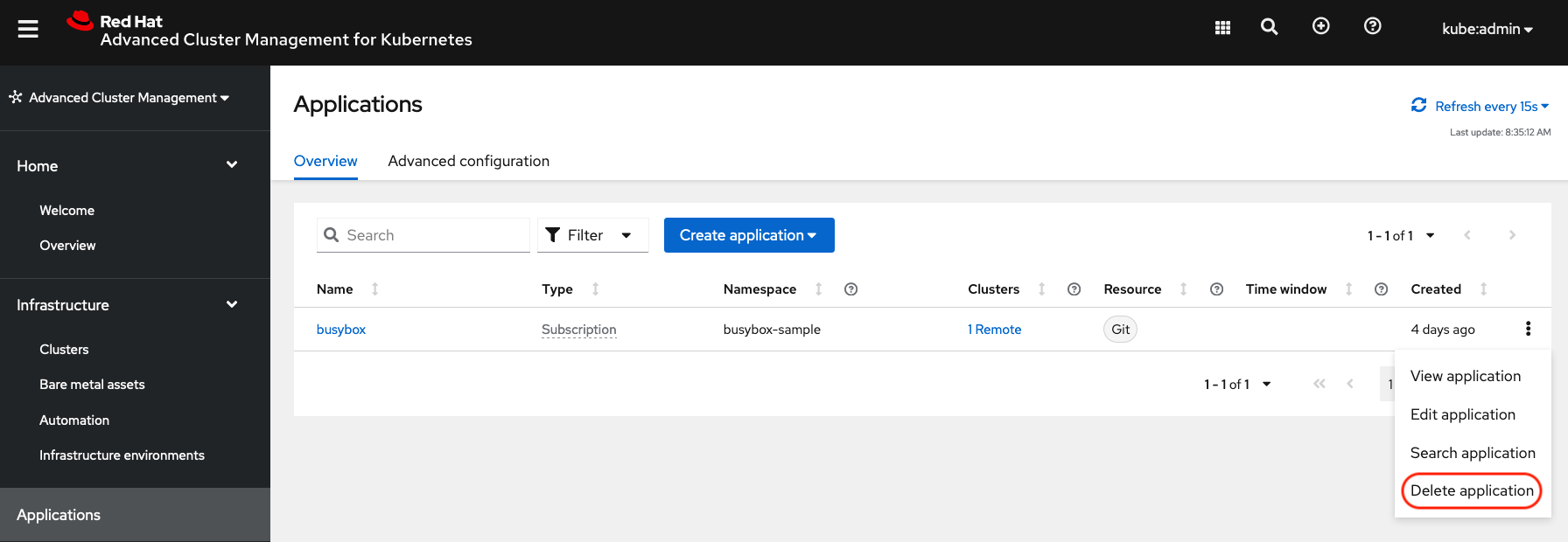
When Delete application is selected a new screen will appear asking if the application related resources should also be deleted. Make sure to check the box to delete the Subscription and PlacementRule.
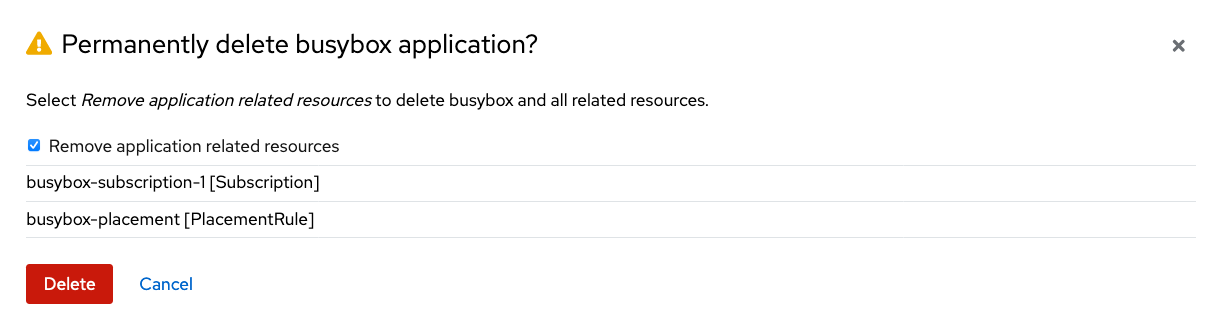
Select Delete in this screen. This will delete the busybox application on the Primary managed cluster (or whatever cluster the application was running on).
In addition to the resources deleted using the ACM console, the DRPlacementControl must also be deleted immediately after deleting the busybox application. Logon to the OpenShift Web console for the Hub cluster. Navigate to Installed Operators for the project busybox-sample. Choose OpenShift DR Hub Operator and the DRPlacementControl.
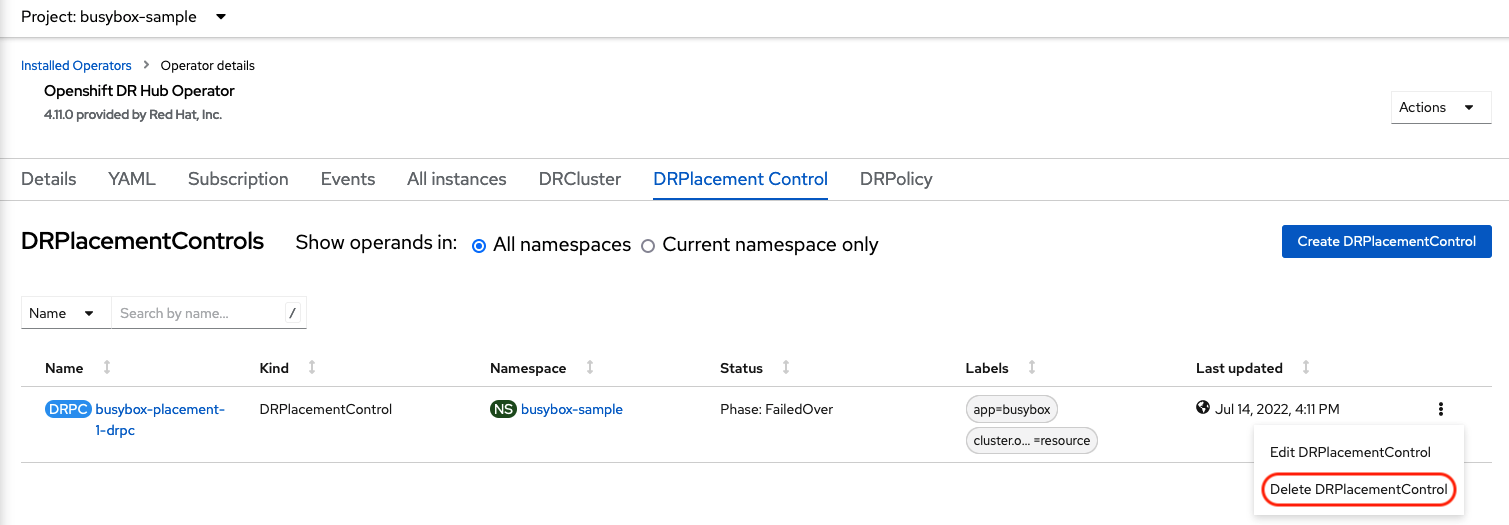
Select Delete DRPlacementControl.
If desired, the DRPlacementControl resource can also be deleted in the application namespace using CLI.
|
| This process can be used to delete any application with a DRPlacementControl resource. |
11. Application Failover between managed clusters
This section will detail how to failover the busybox sample application. The failover method for Metro Disaster Recovery is application based. Each application that is to be protected in this manner must have a corresponding DRPlacementControl in the application namespace as shown in the Apply DRPolicy to Sample Application section.
11.1. Enable Fencing
In order to failover the OpenShift cluster where the application is currently running all applications must be fenced from communicating with the external ODF external storage cluster. This is required to prevent simultaneous writes to the same persistent volume from both managed clusters.
The OpenShift cluster to Fence is the one where the applications are currently running. Edit the DRCluster resource for this cluster on the Hub cluster.
Once the managed cluster is fenced, ALL communication from applications to the ODF external storage cluster will fail and some Pods will be in an unhealthy state (e.g. CreateContainerError, CrashLoopBackOff) on the cluster that is now fenced.
|
Replace <drcluster_name> with your unique name.
|
oc edit drcluster <drcluster_name>apiVersion: ramendr.openshift.io/v1alpha1
kind: DRCluster
metadata:
[...]
spec:
## Add this line
clusterFence: Fenced
cidrs:
[...]
[...]drcluster.ramendr.openshift.io/ocp4perf1 edited11.2. Modify DRPlacementControl to failover
To failover requires modifying the DRPlacementControl YAML view. On the Hub cluster navigate to Installed Operators and then to Openshift DR Hub Operator. Select DRPlacementControl as show below.
Make sure to be in the busybox-sample namespace.
|
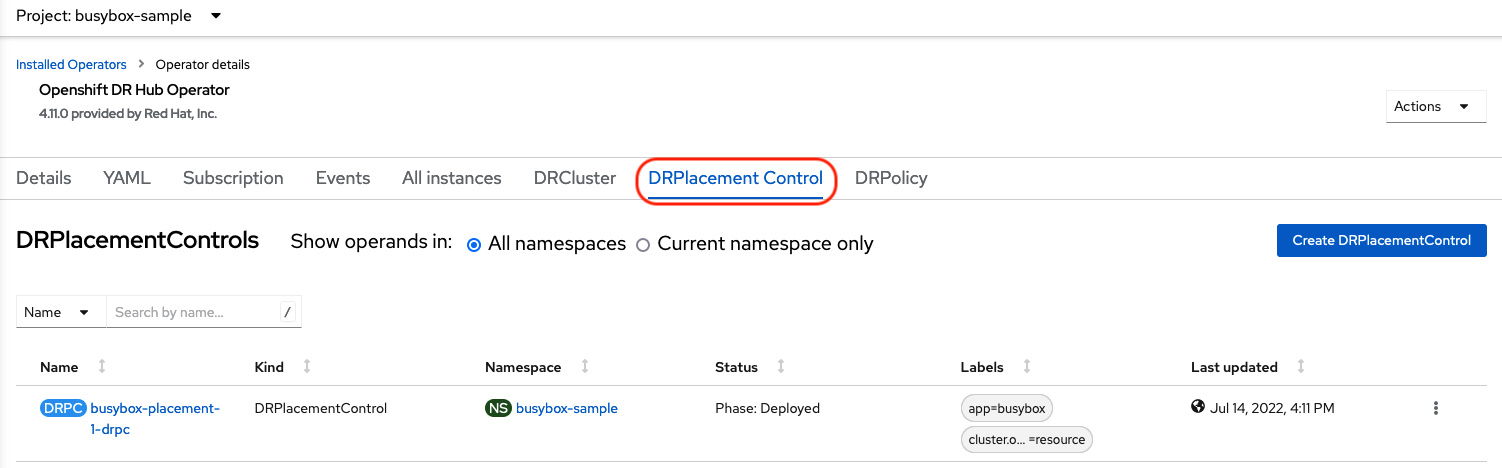
Select busybox-placement-1-drpc and then the YAML view. Add the action and failoverCluster as shown below. The failoverCluster should be the ACM cluster name for the Secondary managed cluster.
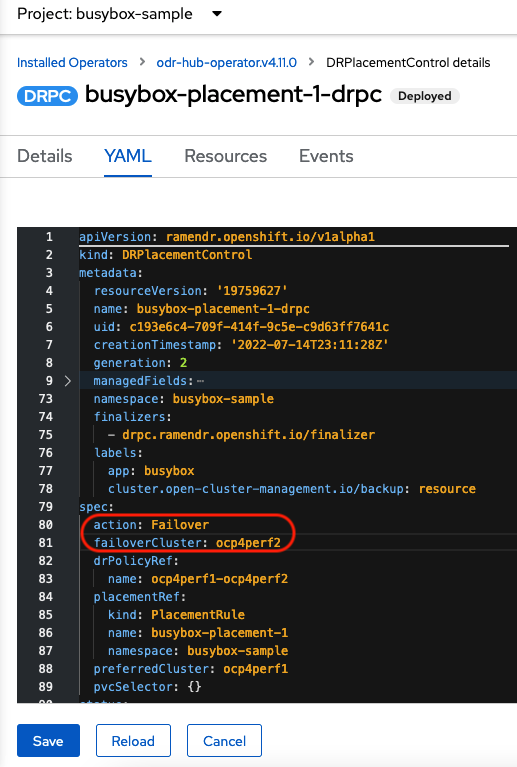
Select Save.
In the failoverCluster specified in the YAML file (i.e., ocp4perf2), see if the application busybox is now running in the Secondary managed cluster using the following command:
oc get pods,pvc -n busybox-sampleNAME READY STATUS RESTARTS AGE
pod/busybox 1/1 Running 0 35s
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
persistentvolumeclaim/busybox-pvc Bound pvc-79f2a74d-6e2c-48fb-9ed9-666b74cfa1bb 5Gi RWO ocs-storagecluster-ceph-rbd 35sNext, using the same command check if busybox is running in the Primary managed cluster. The busybox application should no longer be running on this managed cluster.
oc get pods,pvc -n busybox-sampleNo resources found in busybox-sample namespace.12. Application Failback between managed clusters
A failback operation is very similar to failover. The failback is application based and again uses the DRPlacementControl action value to trigger the failback. In this case the action is Relocate to the preferredCluster.
12.1. Disable Fencing
Before a failback or Relocate action can be successful the DRCluster for the Primary managed cluster must be unfenced.
The OpenShift cluster to be Unfenced is the one where applications are not currently running and the cluster that was Fenced earlier.
Edit the DRCluster resource for this cluster on the Hub cluster.
Replace <drcluster_name> with your unique name.
|
oc edit drcluster <drcluster_name>apiVersion: ramendr.openshift.io/v1alpha1
kind: DRCluster
metadata:
[...]
spec:
cidrs:
[...]
## Modify this line
clusterFence: Unfenced
[...]
[...]drcluster.ramendr.openshift.io/ocp4perf1 edited12.1.1. Reboot OCP nodes that were Fenced
This step is required because some application Pods on the prior fenced cluster, in this case the Primary managed cluster, are in an unhealthy state (e.g. CreateContainerError, CrashLoopBackOff). This can be most easily fixed by rebooting all OpenShift nodes for this cluster one at a time.
After all OpenShift nodes are rebooted and again in a Ready status, verify all Pods are in a healthy state by running this command on the Primary managed cluster.
oc get pods -A | egrep -v 'Running|Completed'NAMESPACE NAME READY STATUS RESTARTS AGEThe output for this query should be zero Pods before proceeding to the next step.
| If there are Pods still in an unhealthy status because of severed storage communication, troubleshoot and resolve before continuing. Because the storage cluster is external to OpenShift, it also has to be properly recovered after a site outage for OpenShift applications to be healthy. |
The OpenShift Web Console dashboards and Overview can also be used to assess the health of applications and the external ODF storage cluster. The detailed ODF dashboard is found by navigating to Storage → Data Foundation.
|
12.1.2. Validate Fencing status
Now that the Unfenced cluster is in a healthy state validate the fencing status in the Hub cluster for the Primary managed cluster.
Replace <drcluster_name> with your unique name.
|
oc get drcluster.ramendr.openshift.io <drcluster_name> -o jsonpath='{.status.phase}{"\n"}'Unfenced12.2. Modify DRPlacementControl to failback
To failback requires modifying the DRPlacementControl YAML view. On the Hub cluster navigate to Installed Operators and then to Openshift DR Hub Operator. Select DRPlacementControl as show below.
Make sure to be in the busybox-sample namespace.
|
Select busybox-placement-1-drpc and then the YAML form. Modify the action to Relocate as shown below.
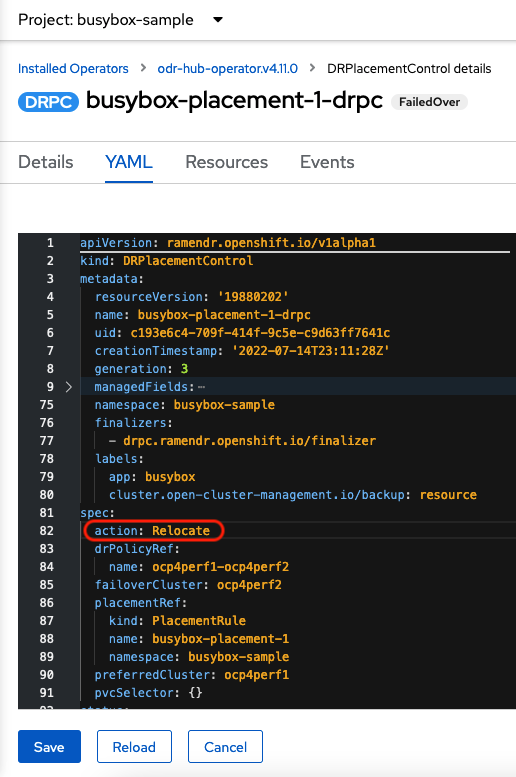
Select Save.
Check if the application busybox is now running in the Primary managed cluster using the following command. The failback is to the preferredCluster which should be where the application was running before the failover operation.
oc get pods,pvc -n busybox-sampleNAME READY STATUS RESTARTS AGE
pod/busybox 1/1 Running 0 60s
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
persistentvolumeclaim/busybox-pvc Bound pvc-79f2a74d-6e2c-48fb-9ed9-666b74cfa1bb 5Gi RWO ocs-storagecluster-ceph-rbd 61sNext, using the same command, check if busybox is running in the Secondary managed cluster. The busybox application should no longer be running on this managed cluster.
oc get pods,pvc -n busybox-sampleNo resources found in busybox-sample namespace.